
Blender offers two primary renderers: EEVEE, a 3D rasterizer utilizing graphics APIs like OpenGL, Metal, Vulkan (in the works); and Cycles, a path tracer that supports CPU and GPGPU APIs such as CUDA, Metal, HIP, and SYCL.
In Cycles, SYCL is currently used solely to target Intel GPUs, but one of SYCL’s goal is to deliver high performance across various GPU vendors.
Is this goal currently achieved with Cycles? That’s actually easy to try, let’s see!
Ever since we’ve introduced SYCL support in 2022, we already had put a lot in place to keep this multi-vendors support in, and we tried to avoid introducing Intel GPUs specific changes that would break it.
Such things could still ended up in the codebase, breaking or lowering runtime performance.
I’ve recently went on testing this support again, and cleaned up a few of them in the past weeks:
- Cycles: oneAPI: Use max_compute_units in get_num_multiprocessors
- Fix building for non-Intel SYCL targets without ocloc
- Cycles: oneAPI: Restrict use of experimental copy optimization to L0
- …
So, while it was all already possible with the same steps since Blender 3.3, you’ll run into less issues now with Blender 4.5 alpha 31633d14b53c and newer (from April 4).
Step 1: Get a SYCL compiler with support for AMD and Nvidia GPUs
Blender is using several important oneAPI extensions to SYCL, hence a version of oneAPI DPC++ compiler is required.
Blender is using and providing a self-compiled version of oneAPI DPC++ compiler 6.0.1, with only support for Intel GPUs.
You currently have 3 possibilities to get one with also AMD and Nvidia support:
- Get a binary release of intel/llvm: Linux packages for nightlies do contain AMD and Nvidia GPUs support. These releases are compiled on Ubuntu 22.04 so are compatible with distributions using glibc 2.35 or higher.
- Build your own version of intel/llvm: to get a build supporting AMD and Nvidia GPUs on Windows or any flavor of Linux. Compile time is rather long but the process is straightforward, documented here: https://github.com/intel/llvm/blob/acf6d3ba65aed812e3f27e487e5028c62ceac5e1/sycl/doc/GetStartedGuide.md
- HIP on Windows can work almost straight since https://github.com/intel/llvm/commit/999c682f583faf05ed5f6091b8c4946daed7d1bd. It has one remaining compilation issue with
__vectorcall, worked on in https://github.com/intel/llvm/issues/7738
- HIP on Windows can work almost straight since https://github.com/intel/llvm/commit/999c682f583faf05ed5f6091b8c4946daed7d1bd. It has one remaining compilation issue with
- Get the proprietary version from intel.com, with the Codeplay plugins: https://codeplay.com/solutions/oneapi/plugins/
On my end, I went with option 2, on Windows, using Cuda 12.8, HIP SDK 6.2.4, VS2022 17.12.1, and nightly-2025-04-01@intel/llvm.
Step 2: Build Blender with specific CMake options
You should follow the standard’s Blender documentation: https://developer.blender.org/docs/handbook/building_blender/
Once done, you can come back and diverge from the default configuration, and edit your CMake configuration with:
SYCL_ROOT_DIR=your path to oneAPI DPC++ compilerWITH_CYCLES_EMBREE=OFF# Embree is not supported on Nvidia and AMD backends and there is currently no logic to disable it per-targetCYCLES_ONEAPI_SYCL_TARGETS=amdgcn-amd-amdhsa;nvptx64-nvidia-cuda;spir64_genCYCLES_ONEAPI_SYCL_OPTIONS_amdgcn-amd-amdhsa=--offload-arch=gfx1032CYCLES_ONEAPI_SYCL_OPTIONS_nvptx64-nvidia-cuda=--offload-arch=sm_86
Where gfx1032 and sm_86 correspond to the AMD and Nvidia devices you want to build for.
In this case, newer sm_9x and higher nvidia devices will still run after recompiling from the embed PTX, but there is no such mechanism for AMD, so make sure to pick the right device. (Yes, that’s quite a blocking issue if you want your build to be able to run on various AMD devices).
Step 3: Set CYCLES_ONEAPI_ALL_DEVICES environment variable and run
To avoid having enumeration issues and users complaining about failures on unsupported devices, only recent Intel GPUs are made accessible out of the box in Blender.
To remove this limitation and show more SYCL devices, set CYCLES_ONEAPI_ALL_DEVICES=1 environment variable before running Blender.
Step 4: Profit and Measure
All devices can be now selected in System->Preferences.
Rendering can even happen concurrently on these various devices but Cycles scales well across devices only when their performance is equal, so using such Blender build for this purpose is not necessarily a good idea.
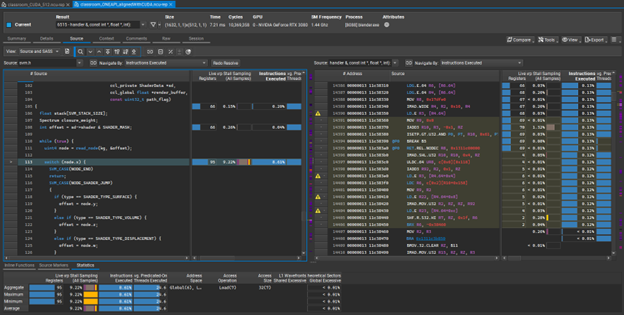
What’s more interesting is that you can use native vendor tools for debugging and profiling, such as Nvidia Nsight Compute below, with proper source linking when compiling with -g:
And how is performance, at the moment?
It’s competitive! See below a comparison of the speed on a RTX3080:
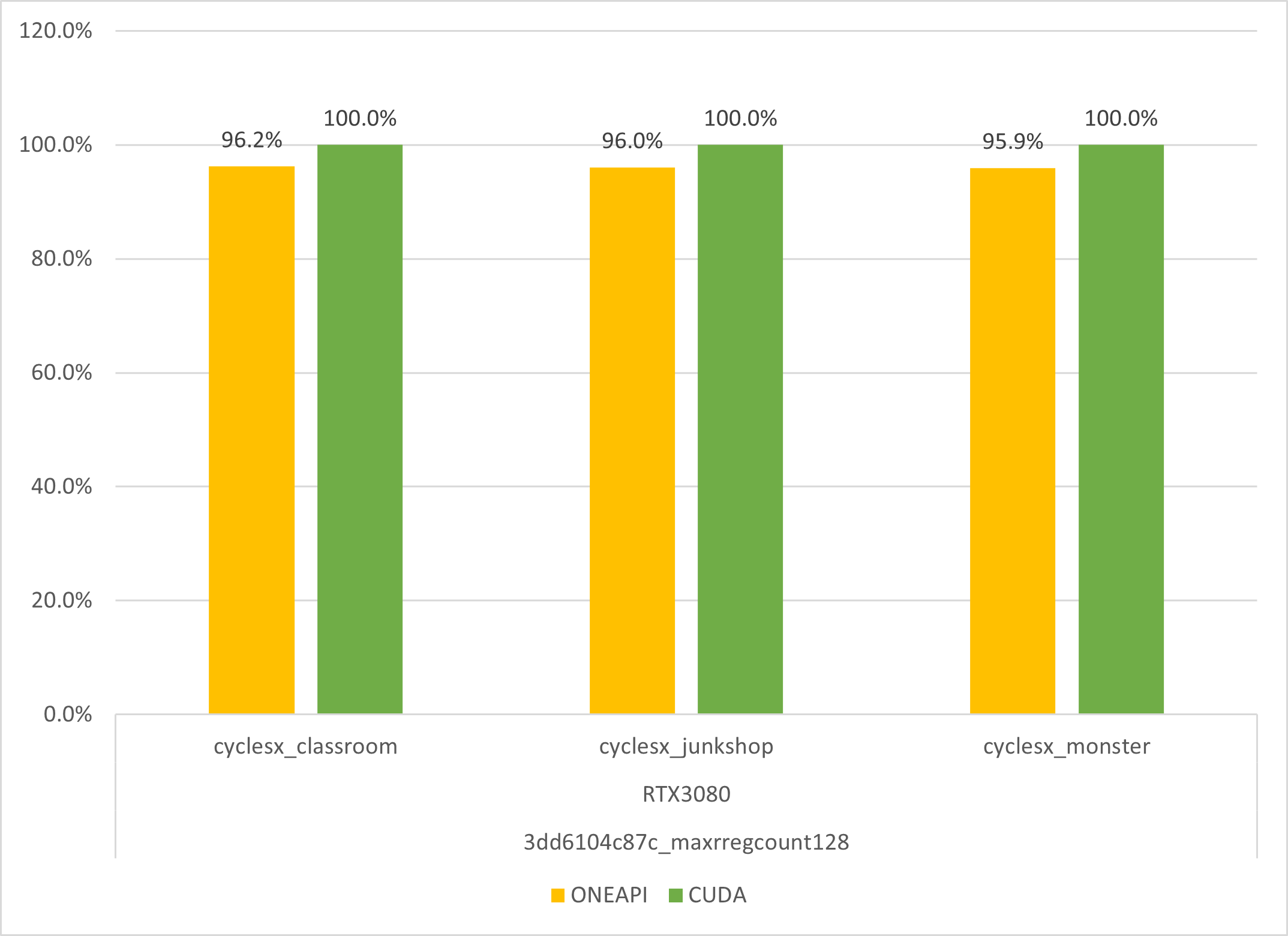
I’ve deviated from the original build by also adding CMake option SYCL_CPP_FLAGS=-Xcudaptxas --maxrregcount=128, as it’s what ptxas chooses with native CUDA, and it gives a good speedup.
Such comparison between oneAPI and CUDA is fair and shows how good SYCL is already.
Is there a catch?
Blender Cycles is a bit specific as a good portion of the execution is spent on kernels doing intersection, that can be accelerated using Hardware Ray Tracing.
Hardware Ray Tracing is enabled on Nvidia GPUs when using the OptiX backend instead of the CUDA backend, you can see what it practically means by looking at aggregated kernel times below, generated using --verbose 4 blender argument and CYCLES_PER_KERNEL_PERFORMANCE environment variable.
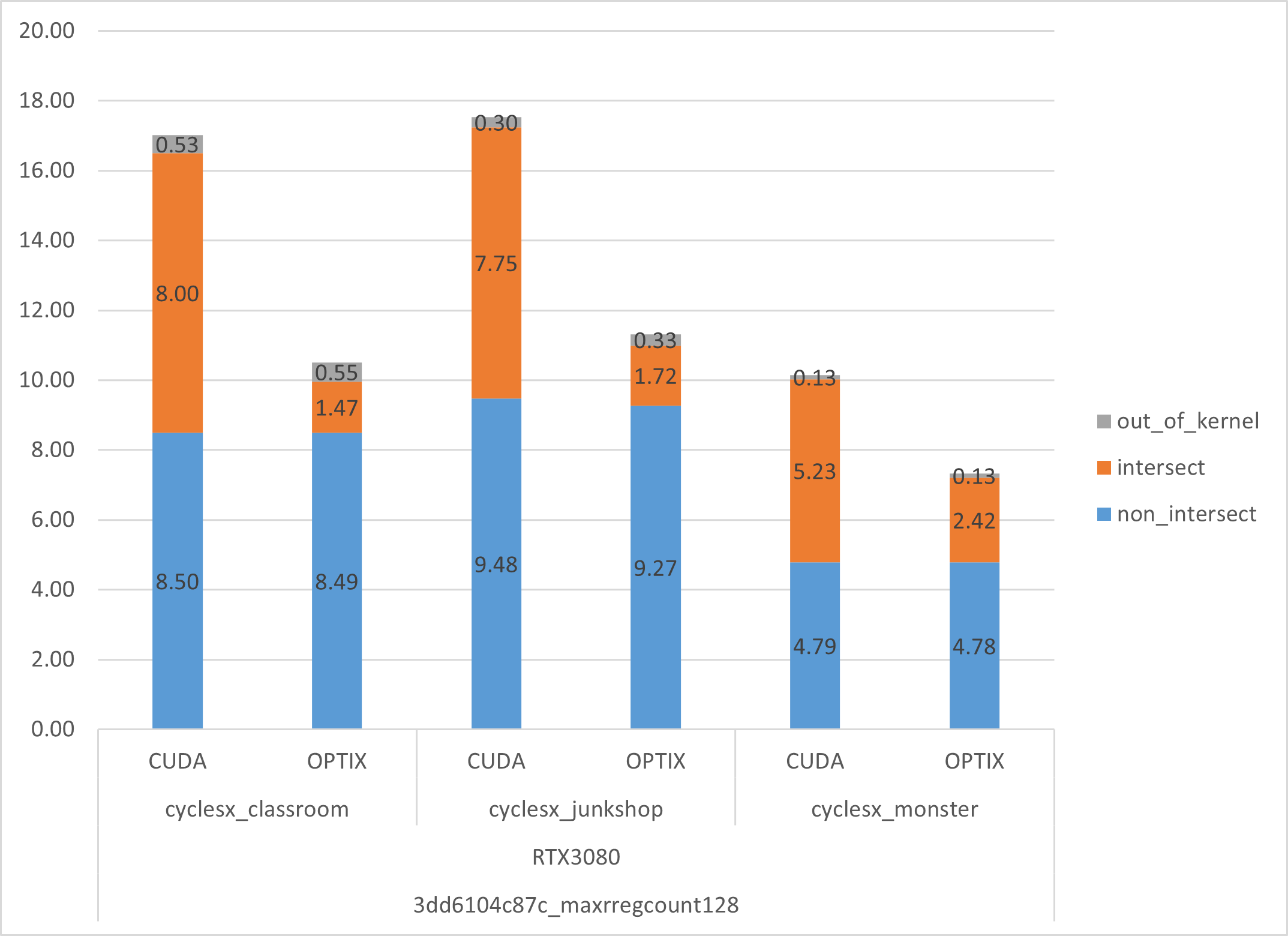
Apart Intel’s Embree that of course does mix well with SYCL, current vendor specific SDKs (OptiX, HIP-RT), as well as cross-platform Vulkan Ray Tracing, cannot be efficiently mixed with anything else. What I mean with “efficiently” here is that, for good performance, we need hardware ray tracing calls to get called inline from the kernels doing intersections, and that’s not something that can be achieved with high-level interoperability.
Nonetheless, it’s pleasing to see SYCL performance for a complex real world code base like Cycles does deliver. Sure, it does so while we don’t take into consideration the intersection kernels relying on hardware acceleration, but this part is a quite specific case.
Troubleshooting typical issues
Compilation errors
clang-offload-wrapper: error: '--offload-compress' option is specified but zstd is not available. The device image will not be compressed.: Blender 4.4 and higher have enabled device images compression so it sets --offload-compress when compiling the kernels library. It’s however quite easy to get a compiler that lacks support for it and unfortunately, it errors out.
I’ve opened a PR to turn the error into a warning: github.com/intel/llvm/pull/17914
Meanwhile, the solution is to build oneAPI DPC++ with LLVM_ENABLE_ZSTD=FORCE_ON instead of LLVM_ENABLE_ZSTD=ON to avoid silently running into this scenario when building the compiler, or to work around it by commenting out --offload-compress --offload-compression-level=19 from ./intern/cycles/kernel/CMakelists.txt.
Devices not enumerating
Devices failing to enumerate can be due to missing runtime dependencies, this can be traced with SYCL_UR_TRACE=1 environment variable, verified with ldd on Linux and https://github.com/lucasg/Dependencies on Windows.
On Linux, Blender calls patchelf --set-rpath $ORIGIN on its versions of all the shared libraries when building them, doing the same should fix most issues. Another temporary solution for testing is to add the compiler’s lib folder to LD_LIBRARY_PATH environment variable.